- Executors - Functions that process inputs and produce outputs, such as prompt templates, LLM calls, or production logic
- Evaluators - Functions that assess outputs against targets or quality criteria, producing numeric scores
- Datasets - Collections of datapoints (test cases) with 3 key elements:
data- Required JSON input sent to the executortarget- Optional reference data sent to the evaluator, typically containing expected outputsmetadata- Optional metadata. This can be used to filter evaluation results in the UI after the evaluation is run.
- Visualization - Tools to track performance trends and detect regressions over time
- Tracing - Automatic recording of execution flow and model invocations
Evaluation Lifecycle
For each datapoint in a dataset:- The executor receives the
dataas input - The executor runs and its output is stored
- Both the executor output and
targetare passed to the evaluator - The evaluator produces either a numeric score or a JSON object with multiple numeric scores
- Results are stored and can be visualized to track performance over time
Evaluation function types
Each executor takes in thedata as it is defined in the datapoints.
Evaluator accepts the output of the executor as its first argument,
and target as it’s defined in the datapoints as the second argument.
This means that the type of the data fields in your datapoints must
match the type of the first parameter of the executor function. Similarly,
the type of the target fields in your datapoints must match the type of
the second parameter of the evaluator function(s).
Python is a bit more permissive. If you see type errors in TypeScript,
make sure the data types and the parameter types match.
For a more precise description, here’s the partial TypeScript type signature of the evaluate function:
Create your first evaluation
Prerequisites
To get the project API key, go to the Laminar dashboard, click the project settings, and generate a project API key. This is available both in the cloud and in the self-hosted version of Laminar. Specify the key atLaminar initialization. If not specified,
Laminar will look for the key in the LMNR_PROJECT_API_KEY environment variable.
Create an evaluation file
- TypeScript
- Python
Create a file named
my-first-evaluation.ts and add the following code:my-first-evaluation.ts
It is important to pass the
config object with instrumentModules to evaluate to ensure that the OpenAI client and any other instrumented modules are instrumented.Run the evaluation
You can run evaluations in two ways: using thelmnr eval CLI or directly executing the evaluation file.
Using the CLI
The Laminar CLI automatically detects top-levelevaluate function calls in your files - you don’t need to wrap them in a main function or any special structure.
- TypeScript
- Python
evals directory with the naming pattern *.eval.{ts,js}:Running as a standalone script
You can also import and callevaluate directly from your application code:
- TypeScript
- Python
evaluate function is flexible and can be used both in standalone scripts processed by the CLI and integrated directly into your application code.
No need to initialize Laminar -
evaluate automatically initializes Laminar behind the scenes. All instrumented function calls and model invocations are traced without any additional setup.View evaluation results
When you run an evaluation from the CLI, Laminar will output the link to the dashboard where you can view the evaluation results. Laminar stores every evaluation result. A run for every datapoint is represented as a trace. You can view the results and corresponding traces in the evaluations page.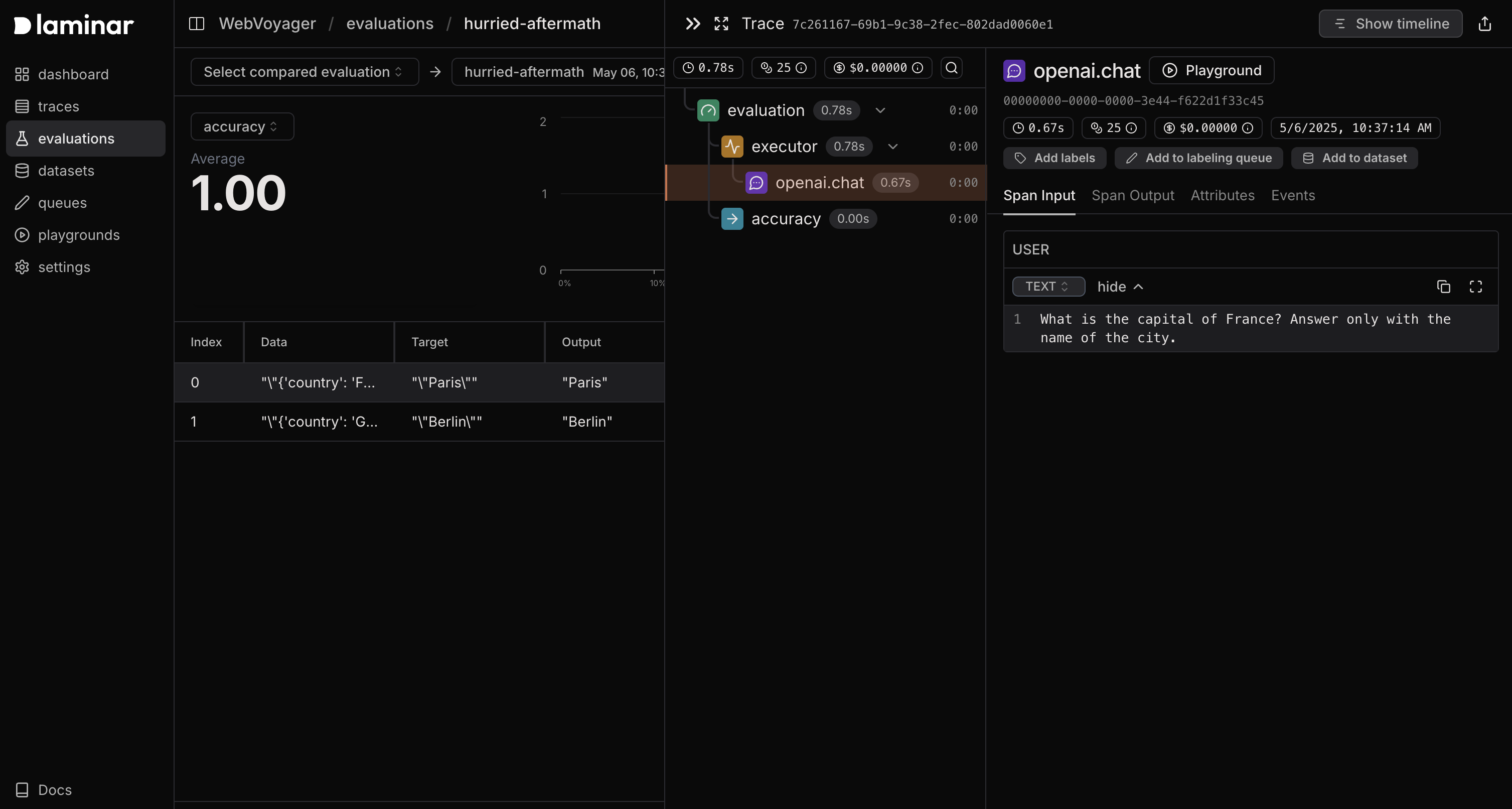
Tracking evaluation progress
To track the score progression over time or compare evaluations side-by-side, you need to group them together. This can be achieved by passing thegroupName parameter to the evaluate function.
- TypeScript
- Python