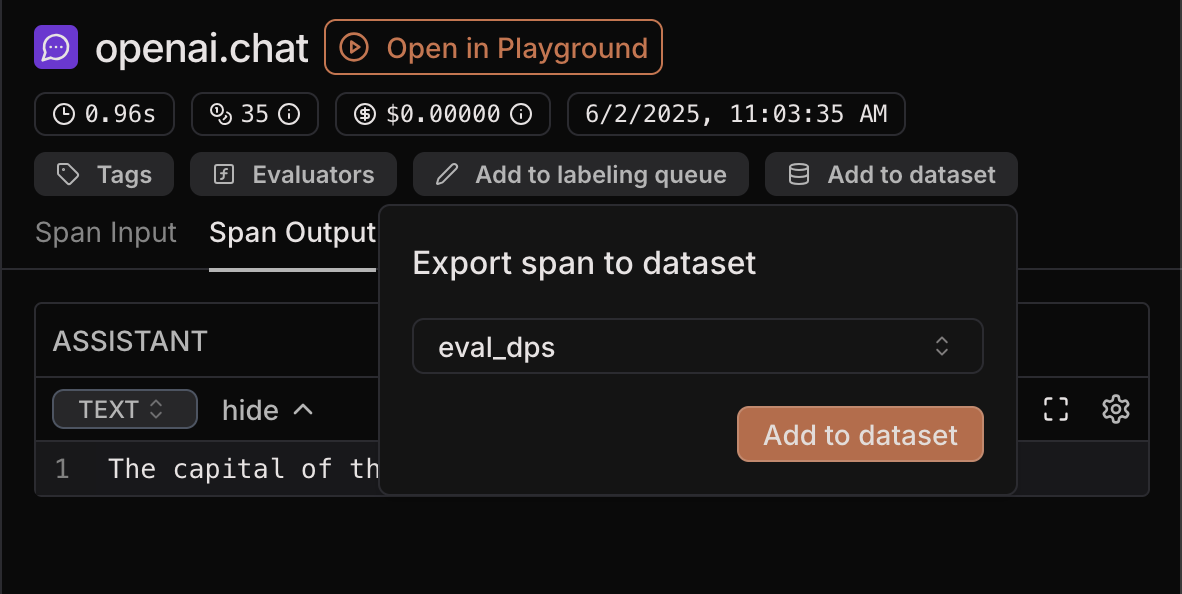
1. Export from a span
You can export a span as a datapoint from both Traces and Evaluation traces. To do so, select a span and click “Add to dataset” in the top right corner. Select the dataset you want to export to and click “Add to dataset”. This will fill thedata field of the datapoint with the input of the span and
the target field with the output of the span.
2. File upload
You can upload datapoints from a structured file with datapoints. To do that, click “Add from source” at the top of the Datasets page. Then, select in the tab whether you want to upload in a structured or unstructured way.File format
Supported file formats are:.csv, .json, .jsonl. We infer the format based on the file extension.
- csv - header is required, default separator and minimal quoting are assumed. If a row has an empty value or less values than headers, missing values will be filled with empty strings.
- json - the file must contain one array of datapoints.
- jsonlines - every line must contain one datapoint.
- If keys are
"data","target","metadata", and"id", we place them in the corresponding fields.- If we cannot parse
"id"as UUID, we assign it a new random UUID.
- If we cannot parse
- Otherwise, all keys and values will go inside
"data".
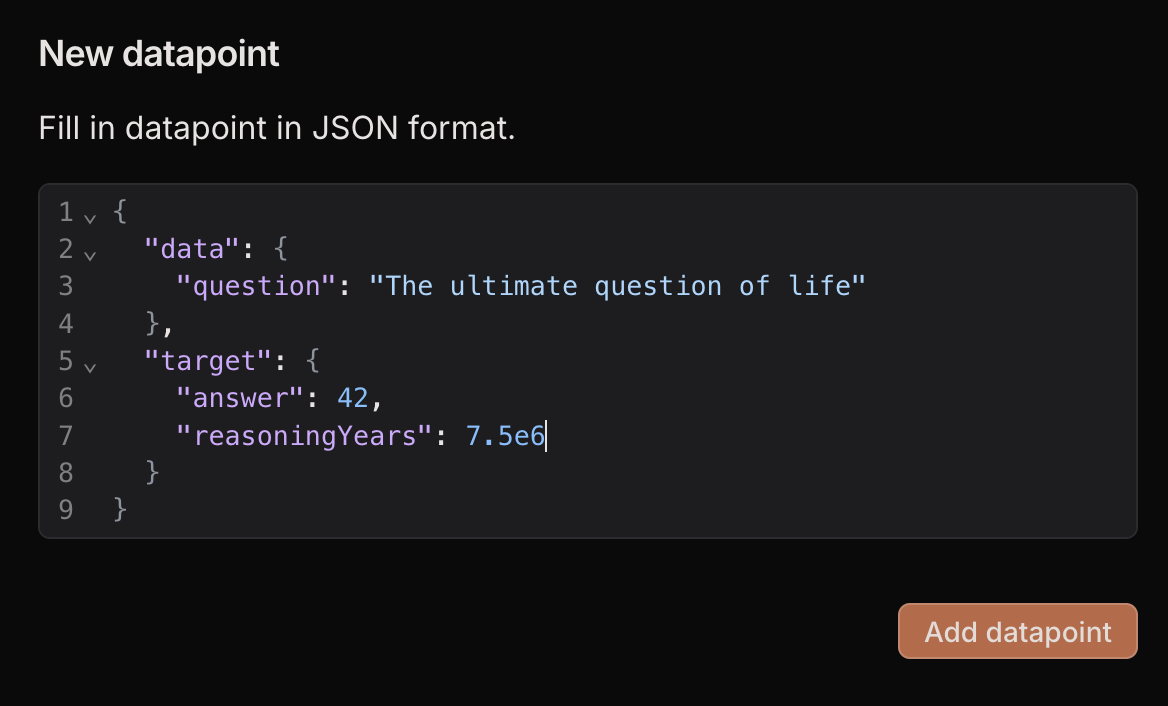
3. Add manually
Click “Add row” at the top of the Datasets page and new empty row will be added. You can any value as long as it is a valid JSON that contains adata field.