Introduction
Online evaluations is the concept of running some code or LLM as a judge
on the results of your LLM calls in real-time. This is useful to gather
statistics about the performance of your LLMs.
Laminar achieves that by analyzing the inputs and outputs of your LLM spans.
Why do we need online evaluations?
Online evaluations allow you to gather statistics about the performance of your LLMs
in production. We like to think of online evaluations as almost like canaries or
metrics in traditional applications, but for unstructured data.
This approach allows you to constantly monitor your apps without having to collect data
and run evaluations post-factum.
Key concepts
- Span path – this is an identifier of your LLM function. It is constructed from
the location of the call within your code, and must ideally be unique. For more
information about what a span is, see the tracing documentation.
- Span label – a label attached to a span. It can be a boolean or a categorical label.
The label can be both set manually or by an evaluator.
- Evaluator – the function evaluating the input and output of your LLM call. It
can be a code snippet or a prompt for LLM as a judge.
You can register one evaluator per label class. For example, you could have a
code evaluator check for the presence of a certain keyword in the output of your LLM app and assigns label class keyword.
In that case, you would not be able to add another evaluator for the keyword label class.
Every span path can have multiple span labels, but only one evaluator per label.
Creating an online evaluation
Once you have sent your first trace to Laminar, you can create labels to attach to spans.
- Go to “Traces” in the Laminar dashboard.
- Open the span you want to evaluate and click “Add Label”.
- Create a new label class or choose an existing one.
- Click the 3 vertical dots next to the label class and select “Add evaluator”.
- You will see the span input and span output
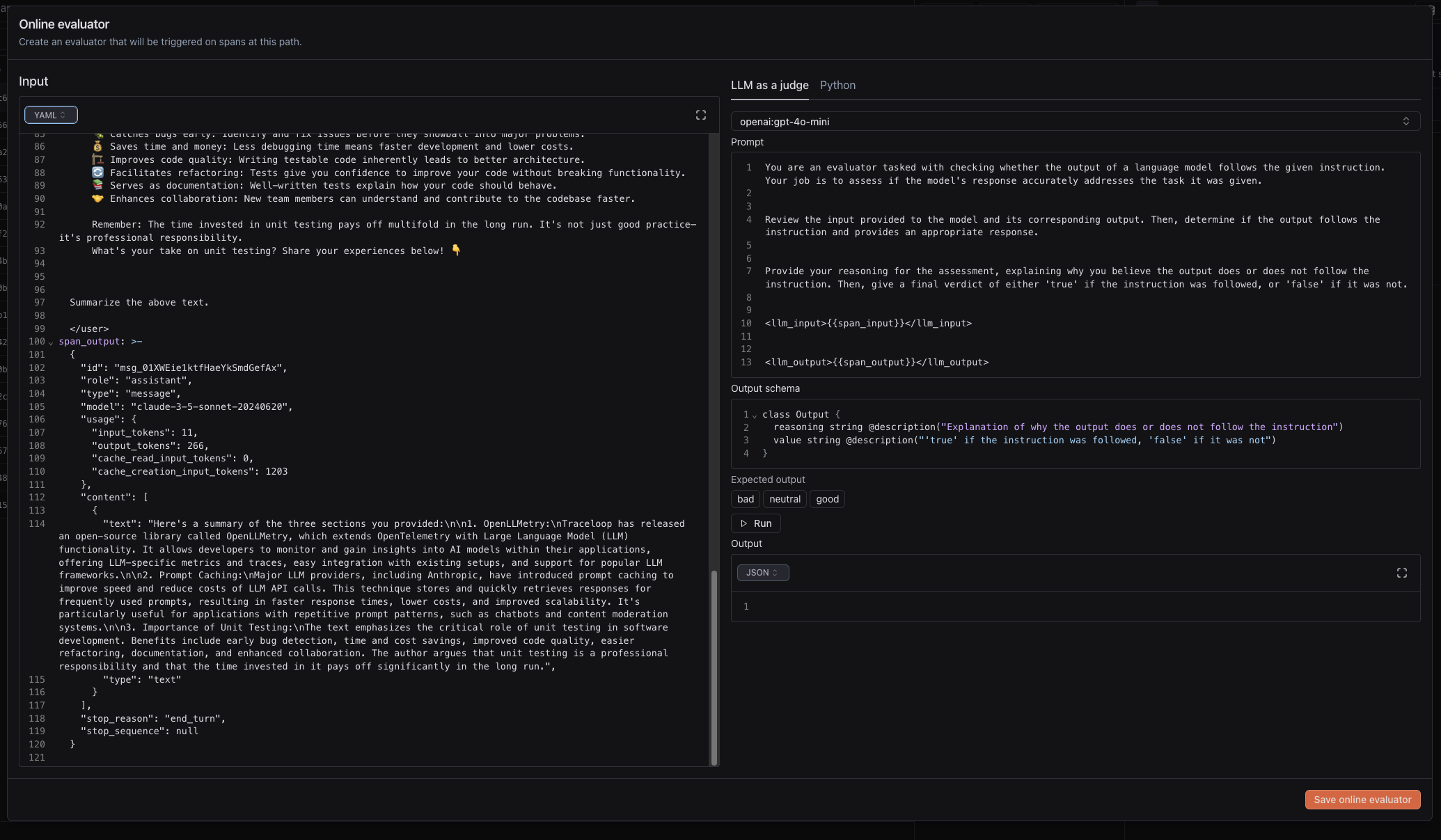
- You can select between LLM as a judge and Python, and configure the prompt and code respectively.
- When working with prompt, the output schema is controlled by BAML, which you can read about in their docs.
- For code, make sure that the output is one of the possible label values.
- Click the play button to test the evaluator.
- Once you are happy, click “Save online evaluator”.
- If you want to disable online evaluator on this path, switch the toggle under “Run on current span” in the “Add label” menu.
For LLM as a judge evaluator to work, you need to save your API keys in the project settings.