Overview
In this guide, we’ll follow the complete journey of building and improving a Data Analysis Assistant - an AI agent that helps users analyze their data, create visualizations, and generate insights. This example showcases how Laminar’s end-to-end platform helps you build reliable tool-calling agents.Why This Guide Matters
Tool-calling agents are powerful but complex - they need to select the right tools, use correct parameters, and handle multi-step workflows. Unlike simple text generation, evaluating these agents requires understanding their decision-making process and systematic improvement based on real user interactions.What You’ll Learn
Step 1: Tracing agent in productionCapture real user interactions automatically to understand how the agent behaves in production. Step 2: Collecting user feedback
Collect user feedback via tagging with Laminar SDK to understand when the agent helps vs. frustrates users. Step 3: Identifying failure patterns with SQL query editor
Identify systematic issues by querying the traced interactions to find failure patterns. Step 4: Label data and create evaluation dataset
Label the problematic cases and create an evaluation dataset using Laminar’s labeling queue interface. Step 5: Running evaluations
Experiment with the agent prompt to see whether the agent is improving with the new prompt. This end-to-end approach ensures our Data Analysis Assistant continuously improves based on real user interactions rather than hypothetical test cases.
The Data Analysis Assistant
Our assistant helps users analyze data through natural language queries like:- “How did our revenue perform last quarter?”
- “Show me user engagement trends over time”
- “Find any anomalies in our conversion rates”
Available Tools
Step 1: Production Tracing with Laminar
First, let’s set up automatic tracing for our Data Analysis Assistant in production:production_agent.py
How Laminar Tracing Works
This agent demonstrates several key tracing concepts:- Top-Level Span: The
@observe(name="analyze_data")decorator creates a top-level span that captures the entire agent execution - Automatic LLM Tracing: Laminar automatically traces the LLM call made via OpenAI API (and other supported popular LLM frameworks and SDKs, such as Langchain, Anthropic, etc.)
- Manual Tool Spans: Each tool execution is wrapped in
Laminar.start_as_current_span(name=tool_name, span_type="TOOL")to create dedicated tool spans
- Which tools were called and in what sequence
- Tool execution results and timing
- All LLM requests/responses throughout the conversation
- Performance metrics and any errors
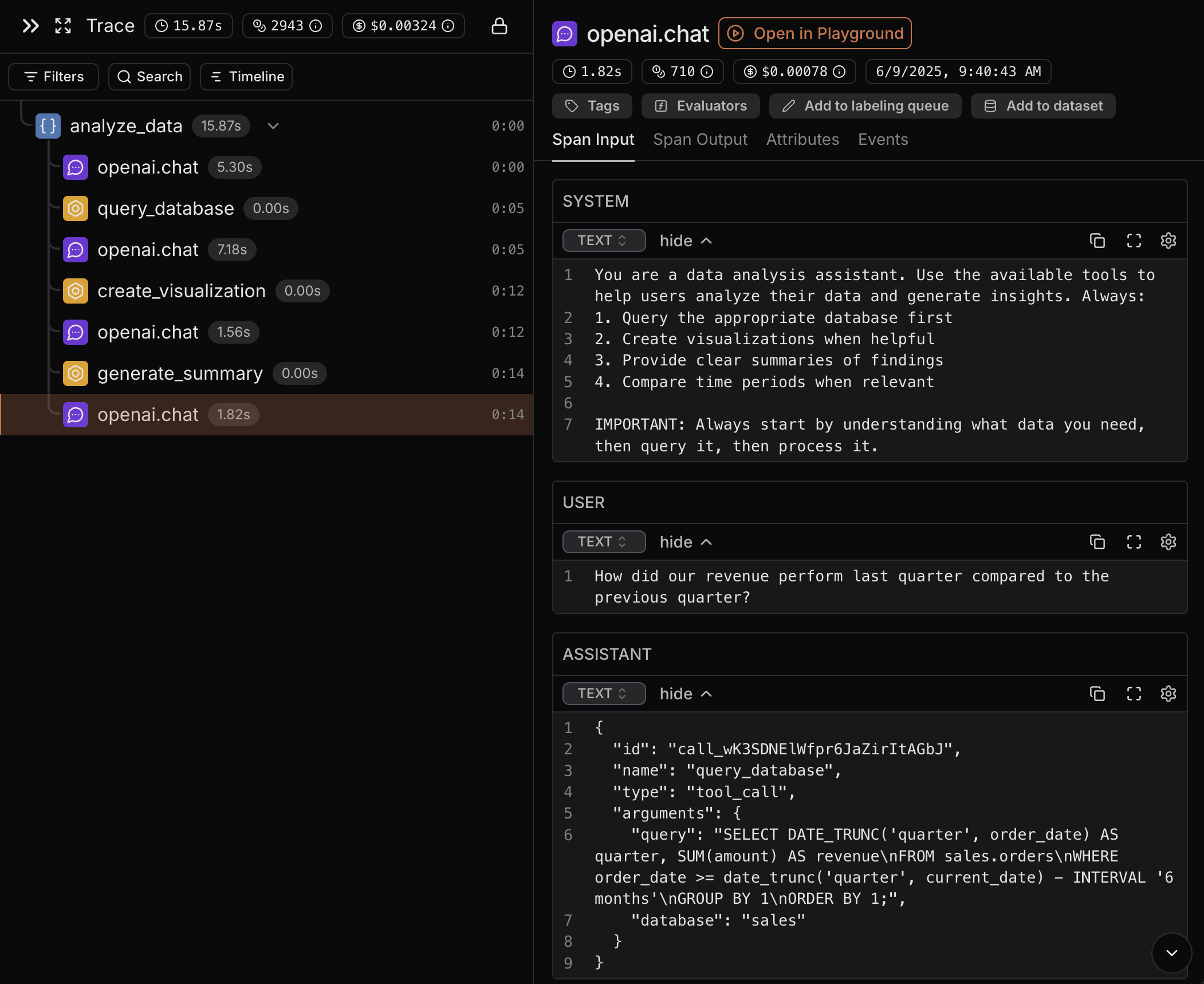
Traced interactions in Laminar
Step 2: Capturing User Feedback
Now let’s add user feedback collection using Laminar’s tagging system. The key is to save the trace ID during execution and tag the trace later when you receive user feedback.production_agent_with_feedback.py
Key Points About Tagging
- Get Trace ID in span context: Call
Laminar.get_trace_id()inside the@observefunction or inside manually created span to capture the trace ID - Store for Later: Save the trace ID along with your session data so you can tag it when feedback arrives
- Tag the Trace: Use
laminar_client.tags.tag(trace_id, tag_name)to apply tags to the entire trace. For example, you can have a user feedback feature in your app that tags the trace withunhelpfulwhen the user provides feedback. - Top-Level Span: When you tag a trace, it applies the tag to the top-level span, making it easy to filter in SQL queries
Step 3: Analyzing Problematic Cases with SQL Editor
After collecting feedback in production, use Laminar’s SQL Editor to identify patterns in unsuccessful interactions. SQL editor is available from any page in Laminar and can be accessed by clicking the “console” button in the top right corner in the navigation bar.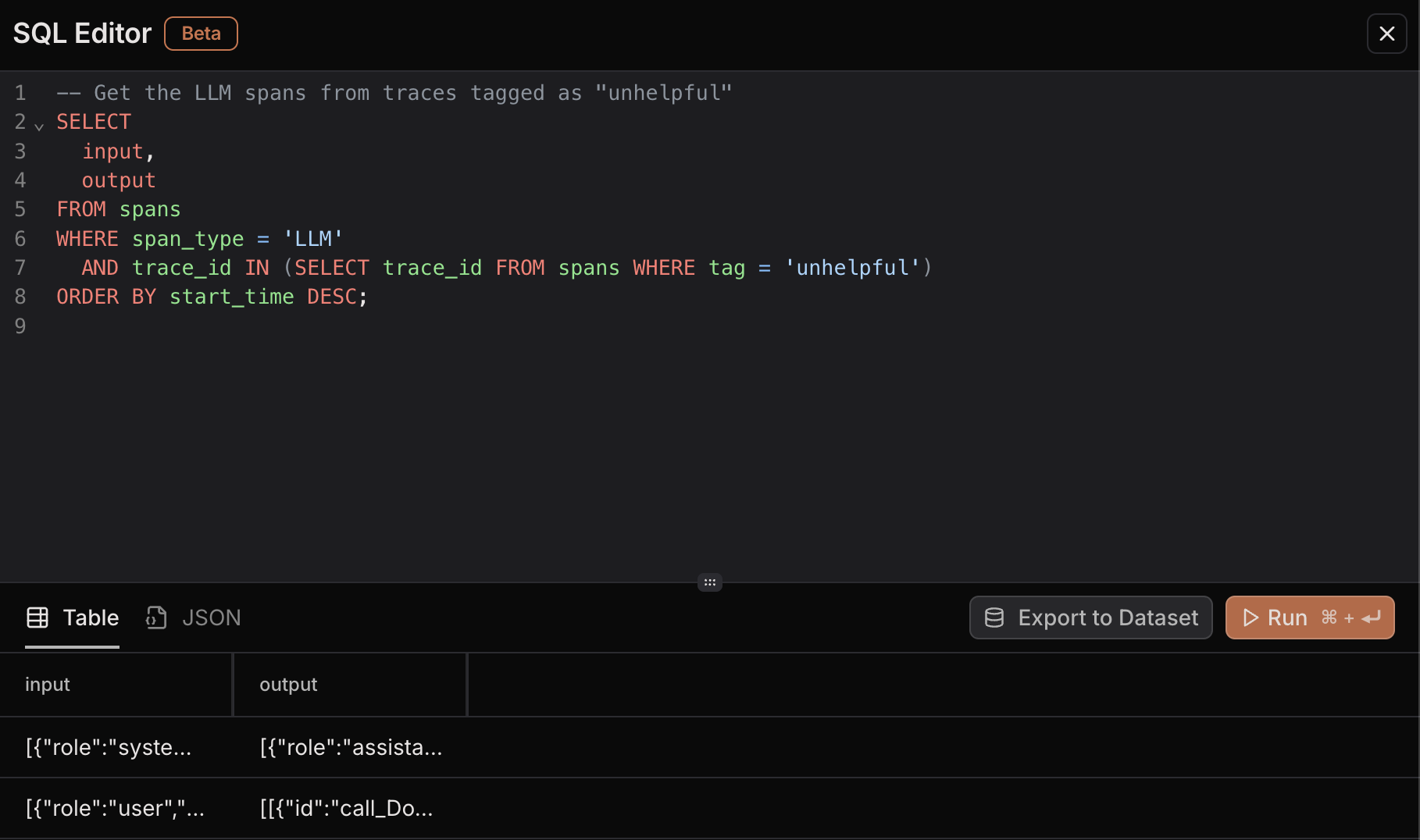
Example of using Laminar's SQL Editor to query traced interactions
export to dataset button to export the results to a dataset.
Drag output field to the target column and input field to the data column.
Then click on the create dataset button to create new dataset.
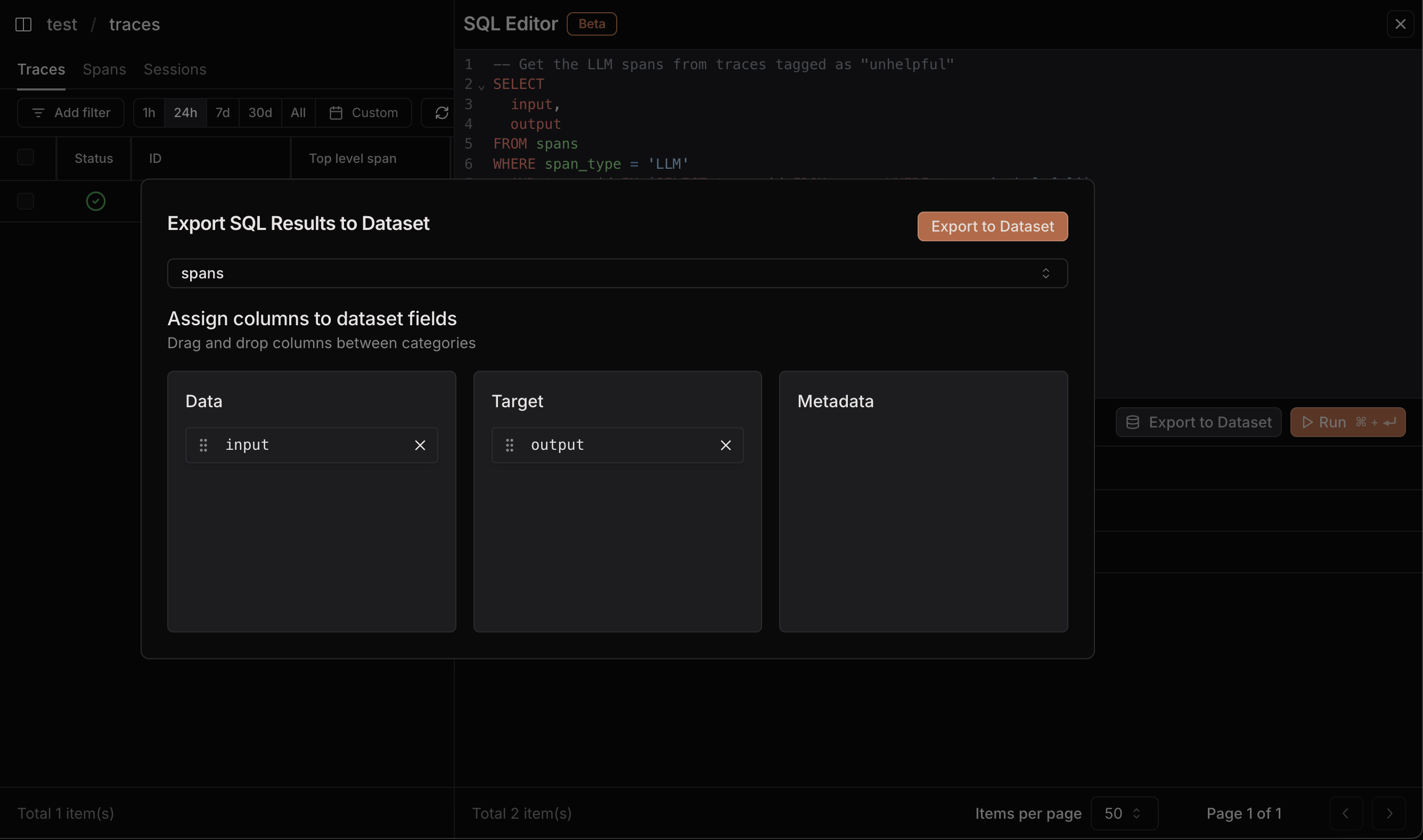
Exporting query results to dataset for labeling
Push dataset to labeling queue
Now navigate to the newly created dataset from the previous step. In the dataset view:- Export to labeling queue: Click the “Add all to labeling queue” button
- Choose labeling queue: Either create a new labeling queue or select an existing one
Step 4: Label data and create evaluation dataset
Laminar provides a convenient split-screen labeling interface that makes it easy to quickly label your data and build evaluation datasets. In this step, we will use labeling queue from the previous step to label the data and create an evaluation dataset.The Labeling Interface
When you open your labeling queue, you’ll see an efficient split-screen interface: Left Panel - Payload View: Shows the full JSON structure of the current item, including the user’s original query in thedata field and the agent’s problematic response in the target field.
Right Panel - Target Editor: This is where you provide the correct expected output. You can:
- Edit the existing response to fix tool selection issues
- Write completely new target responses with correct tool calls
- Use proper JSON formatting with syntax highlighting
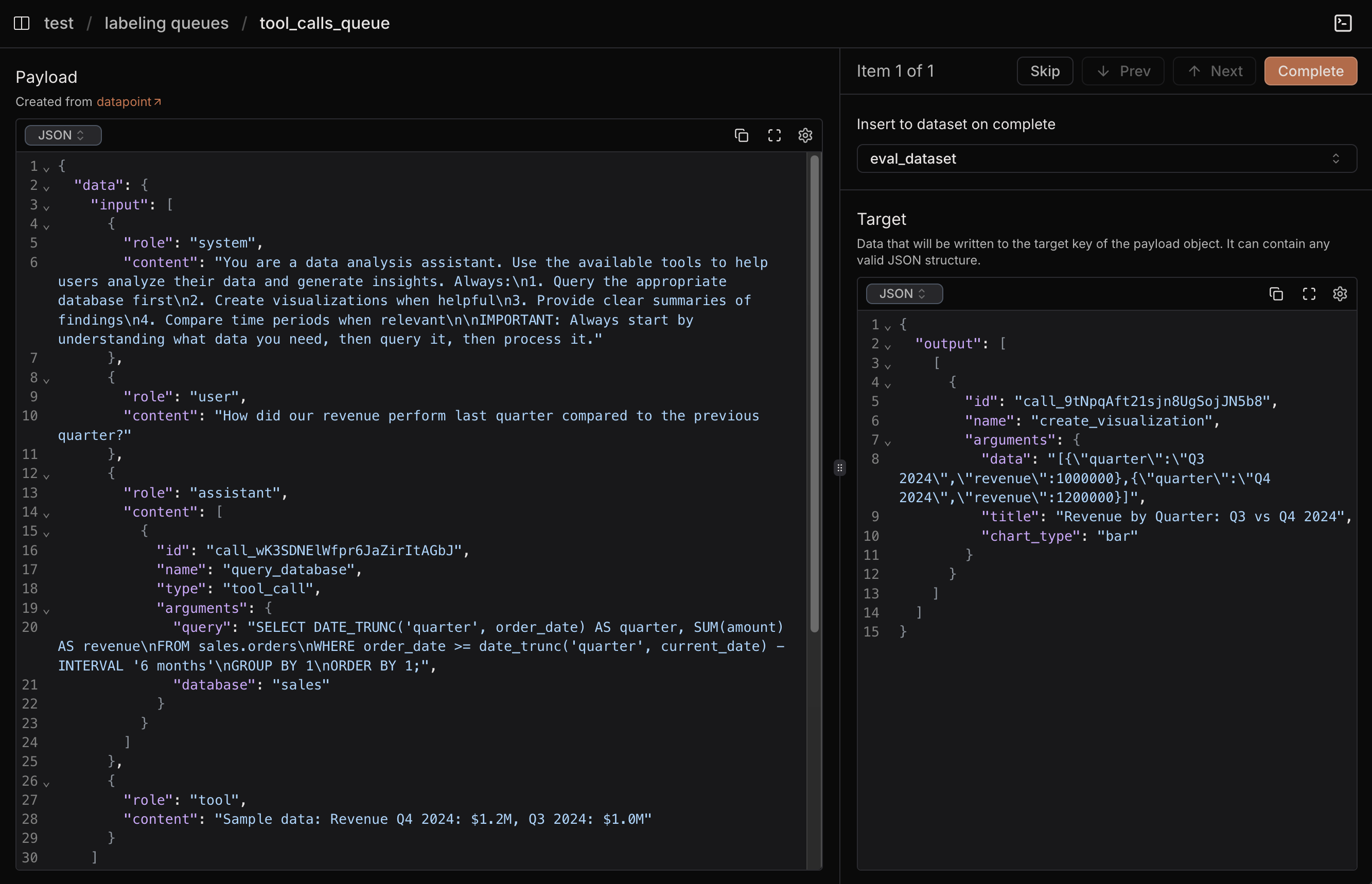
Laminar's labeling interface for tool call evaluation
Labeling Workflow
For each problematic tool call case:- Review the original query in the payload view (left panel)
- Analyze what went wrong with the agent’s response
- Write the correct expected output in the target editor (right panel)
- Select your target dataset from the dropdown. You can create a new dataset or select an existing one.
- Click “Complete” to save and move to the next item
completed datapoint will be automatically added to the target dataset.
This dataset will be used for evaluation in the next step.
As you type in the target editor, the left panel updates in real-time, showing exactly what will be saved to your evaluation dataset. This immediate feedback helps ensure accuracy in your labeling.
Once your dataset is created, we can reference it in evaluations using LaminarDataset("eval_dataset").
Step 5: Running Tool Call Evaluations
With our labeled dataset ready, we can now run systematic evaluations. The key insight is that our dataset contains the original conversation messages in the OpenAI format, which allows us to test different system prompts while keeping the user queries consistent.Understanding the Dataset Structure
From the labeling process, each datapoint in our evaluation dataset has this structure:- Test new system prompts by replacing the system message
- Keep user queries consistent for fair comparison
- Compare against expected tool calls from human labeling
Create evaluation directory structure
Main evaluation file
evals/eval_tool_selection.py
Testing Different System Prompts
The power of this approach is that you can easily test different system prompts:content field in the system message to test different versions and see which performs better on your real production failure cases.
Running the evaluation
You can run this evaluation in two ways:Using the CLI
Running as a standalone script
Viewing Results and Iteration
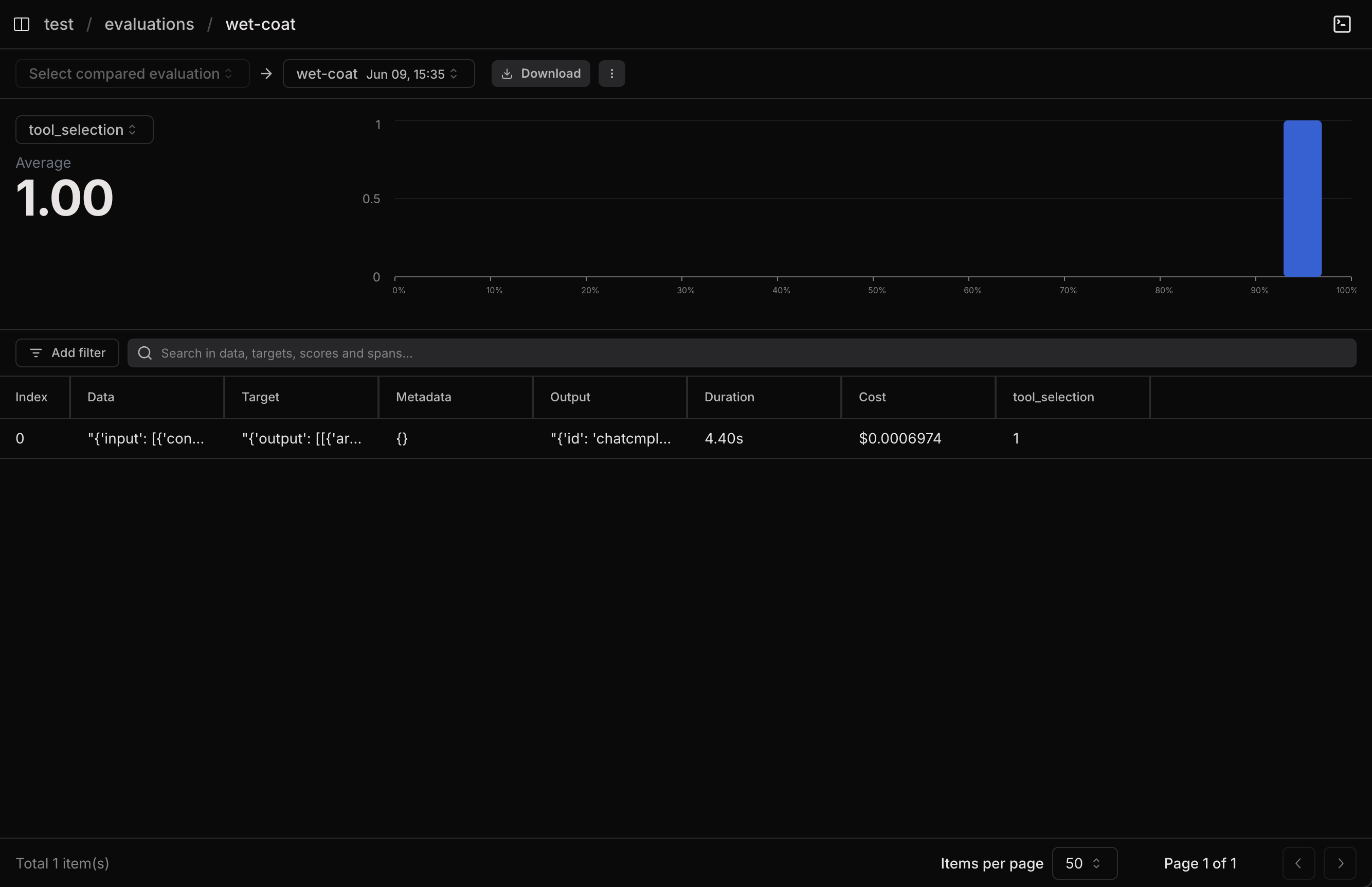
Evaluation results in Laminar
- Overall Scores: How your agent performs across all metrics
- Individual Cases: Traces of each evaluation
- Performance Trends: How scores improve over iterations
- Improve Prompts: Refine system prompts based on failure patterns
- Adjust Tool Selection Logic: Update tool descriptions or parameters
- Add New Tools: Identify missing capabilities from user feedback
- Update Training Data: Create more diverse evaluation cases
Learn More
To dive deeper into the concepts covered in this guide:- Tracing Documentation: Learn more about automatic instrumentation, manual span creation, and advanced tracing patterns
- Evaluations Documentation: Explore advanced evaluation patterns, custom evaluators, and evaluation best practices